ncatでHTTPリクエストの送信中にクライアントの接続を切断する
概要
APIのデバッグにおいて、クライアントサイドで再起動やダウン、ネットワークエラーなどにより、クライアント側でHTTPリクエスト送信中に接続を切断するようなケースを手動で再現したい。 HTTPで通信する場合には、netcatを使って対話的にHTTPリクエストの途中で切断すればこれを再現できる。
しかし、HTTPSで通信する場合には、SSL/TLS Handshakeや暗号化を手動で行うことはできないので、それを肩代わりしてくれるncatを使う必要がある。
実施方法
手元にncatがない場合、docker imageでncatがバンドルされているものを利用できる。
以下のコマンドを実行し、HTTPリクエストを途中まで書き込んでアイドルタイムアウトを待てば、3秒後に自動で切断されるため再現が可能である。
$ docker run --rm -it raesene/ncat -C -i 3000ms --ssl example.com 443 POST / HTTP/1.1 Host: example.com User-Agent: xxx Content-Type: application/json Content-Length: 26
--sslオプションを指定することで、HTTPSで必要なHandshake/暗号化を肩代わりしてくれるので、生のHTTPを記述すれば良い。
参考
Fluentdのout_http pluginでapplication/x-www-form-urlencoded形式のリクエストを送信する
概要
v1.7.0以降のFluentdでデフォルトでバンドルされているout_httpプラグインを利用すると、 HTTP/HTTPS経由でレコードを送信することができる。
out_httpを利用し、
デフォルトで利用可能なformat pluginとContent-Typeの対応
out_httpで送信可能なContent-Typeは、利用可能なformatプラグインに依存しているため、デフォルトでは以下の形式が対応している。
json:application/jsonorapplication/x-ndjsonltsv,tsv:text/csvcsv:text/csvmsgpack:application/x-msgpackout_file,single_value,hash,stdout:text/plain
一見、application/x-www-form-urlencoded での送信ができないように見えるが、
ltsvプラグインを利用することで対応が可能である。
ltsvプラグインによる application/x-www-form-urlencoded 形式でのリクエスト送信
ltsvプラグインには、delimiterとlabel_delimiterのパラメータを渡すことができ、それぞれフィールドのデリミタとラベルのデリミタをカスタムできる。
ltsv形式であるため、デフォルトではそれぞれ\t、:だが、
今回目的を達成するために以下のような設定を行う。
<match>
@type http
endpoint http://xxx
open_timeout 5
read_timeout 5
content_type application/x-www-form-urlencoded
retryable_response_codes 503
...
<format>
@type ltsv
delimiter "&"
label_delimiter "="
add_newline false
</format>
</match>
delimiterに&、label_delimiterに=を設定し、content_typeに application/x-www-form-urlencoded を設定する。
add_newlineは、レコードの最後に改行を入れるか入れないかを設定するものであり、ここではfalseとしておく。
これだけでは不十分でout_httpで送信されるリクエストは、 Fluentdのバッファで管理されているチャンク毎にまとめてリクエストすることになる。 これはout_httpがバッファリングを行うバッファOutputプラグインであるためであり、 バッファを通さずにリクエストする方法は提供されていない。
そのため、単一のレコードのみを受け付けるような既存のAPIに上手く適合させるには、 リクエストが単一のレコードのみを含むことを保証させる必要がある。
バッファプラグイン設定により単一レコードでのリクエストを保証
先ほどの設定に、新たにbufferディレクティブを追加しています。
<match>
@type http
endpoint http://xxx
open_timeout 5
read_timeout 5
content_type application/x-www-form-urlencoded
retryable_response_codes 503
<buffer uniqueId>
@type memory
queued_chunks_limit_size 100
flush_mode immediate
flush_thread_count 8
chunk_limit_records 1
total_limit_size 512m
overflow_action block
</buffer>
<format>
@type ltsv
delimiter "&"
label_delimiter "="
add_newline false
</format>
</match>
バッファプラグインとしてmemoryを利用し、flush_modeをimmediate、chunk_limit_recordsを1、overflow_actionをblockとすることで、リクエスト単位をまとめるチャンクの中に含まれるレコードを1つに限定し、チャンクに1件追加された時点で即時フラッシュを行い、フラッシュが詰まっている場合に後続のデータが到着した場合でもブロックするようにします。
bufferディレクティブに渡しているuniqueIdは、適当にユニークなIDを指定します。
完全にユニークである必要はありません。
チャンクの中に入るレコードが1つであるため、これをユニークにすることで、レコード毎に異なるチャンクに格納されることになります。
加えて、デフォルトが1であるqueued_chunks_limit_size/flush_thread_countを増加させることで、リクエストの並列度を増加させます。
もしqueued_chunks_limit_sizeが1の場合、1つのレコードが送信完了するまで新しいチャンクに新しいレコードを入れることができず、リクエスト送信でボトルネックになってしまいます。
ここでは仮に最大100個のチャンクを許容していますが、例えばバッファプラグインがfileだと100つのチャンクがファイルに読み書きすることになり、ディスクIOが余計に多くなってしまいます。 これを回避するためにmemoryとしていますが、リクエストの送信に失敗したり途中でFluentdがダウンすることで、チャンクに入れられたレコードがロストする可能性があることに注意してください。 ロストが許容できない場合にはこの選択はできません。
ここまでで、単一のレコード毎にHTTPでapplication/x-www-form-urlencoded形式のリクエストが可能になったように見えます。 まだこれでは不十分で、out_httpは送信するレコードのフィールドの値をURIエンコードしないという問題があります。 例えば、送信するレコードの中にスペースを含んでいたり日本語を含んでいる場合は、受信側のAPI側で正しくリクエストボディを解釈することができません。
Fluentdのrecord_transformerでフィールドをURIエンコードする
事前に送信するフィールドの値をrecord_transformer filterプラグインでURIエンコードしておきます。
<filter>
@type record_transformer
enable_ruby
<record>
...
text ${require "uri"; URI.encode_www_form_component(record["text"])}
...
</record>
</filter>
RubyのURIモジュールを読み込み、encode_www_form_componentを呼び出すことで個別のフィールドについてURIエンコードを適用します。
enable_rubyによる変換は比較的パフォーマンスが低いということもあり、
追加のプラグインが利用可能な場合にはそちらを優先する必要があります。
まとめ
デフォルトでバンドルされているout_httpプラグインでも、ltsvフォーマットプラグインをカスタムすれば、レコードをapplication/x-www-form-urlencoded形式にフォーマットすることが可能です。 バッファプラグインをカスタムすることで、単一のレコードにつき単一のリクエストで送信することができ、既存のAPIに対して連携を行う場合にも適用できます。 各フィールドがURIエンコードが必要な場合は、record_transformerプラグインでRubyのURIエンコードを実施することで適用できます。
いずれにせよ、このような設定で対応する場合は、レコードのロストやパフォーマンス上の懸念がない場合に適用可能です。必要に応じて追加のプラグインの利用や開発を検討する必要があります。
Hive on TezにおいてDISTRIBUTE BY指定したクエリのFile Mergeの挙動
Hive on Tezにおいて、DISTRIBUTE BYを指定したクエリが、File Mergeが有効化されていたことによって想定外の挙動になった。 Hiveのバージョンは、3.1.3でORC形式のテーブルを想定している。また、他のバージョンでは修正されている可能性はある。
まず、DISTRIBUTE BYの挙動からおさらいしておくと、DISTRIBUTE BYに指定したカラムについて、カラムの値が同じであれば同じReducerで処理されることを保証するものである。また、競合を避けるためにReducerの単位で別のファイルに結果が書かれることになる。 つまりは、DISTRIBUTE BYで指定したカラムについて、同じ値を持つレコードは、必ず同じファイルに書かれるということが保証される。
LanguageManual SortBy - Apache Hive - Apache Software Foundation
Sort By, Order By, Distribute By, and Cluster By in Hive - SQLRelease
これはHive on TezでもHive on MapReduceでも同じことである。
HiveではORDER BYをつけることでデータ全てが一貫してソートされているグローバルソートを実現できるが、全てのデータを1箇所でソートする必要があるため、当然Reducerの数も1つに制限されてしまう。書き込み先のファイルが1つになるため、データサイズが大きい場合に容易にボトルネックとなる。 そこで、グローバルソートは不要だが、特定のカラム単位では一貫したソート結果が欲しいと言うようなケースで、このDISTRIBUTE BYとSORT BYを組み合わせることで、Reducerごとのソートを可能とすることができる。
しかし、Small FIle Problemを避けるためにhive.merge.tezfilesがtrueになっている環境下においては、この挙動が変わってしまうと言うことが観測された。
hive.merge.tezfilesをtrueにしていると、そうではない場合のFile MergeのためのReducerが追加される。
ここまでは良いが、Hive3.1.3では、その前段までは保持されていたDISTRIBUTE BYのコンテキストが、File Mergeの時点では失われてしまい、完全に無視されてファイルマージが行われてしまうということが分かった。
つまり、ファイルマージされる前まではReducer単位でのソートができていたが、その後ファイルサイズを最適化するために、前段のファイルを分割/結合して、マージすることになる。
ファイル単位での単なる結合であれば、これはReducer毎のソートを維持したまま達成可能である。しかし分割が行われた時点でこの保証は無くなってしまう。
ORCのストライプレベルでのファイルマージを制御するhive.merge.orcfile.stripe.level フラグをfalseにした場合でも、やはりファイル分割が行われてしまった。
結果として、Reducer毎のソートは無効になってしまい、異なるファイルに同じDISTRIBUTE BYカラムを持つレコードが分割して含まれてしまうと言う問題が発生する。
こういった問題を避けつつ、Small File Problemも一定数解決したい場合には、
set hive.merge.tezfiles=false; set hive.exec.reducers.max=xxx;
のように指定を行い、ファイルマージを回避しつつ、Reducerの数を減らすことでなるべくパフォーマンスを落とさずにファイル数を少なくすると言うチューニングが考えられる。
HiveServer3.1.3をローカルデバッグする
今回、Hive3.1.3をDocker上で立ち上げ、HiveServerにリモートデバッガをアタッチしてHiveServerの処理を詳細にデバッグする環境をセットアップします。開発環境はIntelliJを前提としてます。
公式にHive用のDockerImageを提供するIssueがHive4.0.0で導入されており、この周辺のコードを流用します。
- [HIVE-26400] Provide docker images for Hive - ASF JIRA
- hive/packaging/src/docker at dd3fd775406c2d621c42ef1adce2fa0f3b9acd39 · apache/hive · GitHub
まず、試しに現時点でのmasterをcloneしてきて、README.mdに従ってビルドします。
cd packaging/src/docker ./build.sh -hive 3.1.3
Docker上で動作するHiveServerにデバッガをアタッチするため、HADOOP_OPTSにデバッグエージェンを起動するための環境変数を設定します。HiveServerはJava8で動作するため、address=*:8888のような表記ではなくaddress=8888と記述しないとエラーが起きることに注意してください。
docker run -d -p 10000:10000 -p 10002:10002 -p 8888:8888 --env SERVICE_NAME=hiveserver2 --env HADOOP_OPTS="-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=8888" --name hiveserver2-standalone apache/hive:${HIVE_VERSION}
ここで、起動直後に Schema initialization failed! のエラーが発生してしまうため、修正する必要があります。
hive3.1.3時点でのschematoolの引数と、最新のmasterのschematoolの引数が異なるため、Metastoreの初期化に失敗してしまいます。
上記の行を、以下の行に変更し、Docker Imageを再度ビルドする必要があります。
$HIVE_HOME/bin/schematool -dbType $DB_DRIVER -initSchema
ビルドが完了したら、以下のコマンドを再度実行し、HiveServerを起動します。
docker run -d -p 10000:10000 -p 10002:10002 -p 8888:8888 --env SERVICE_NAME=hiveserver2 --env HADOOP_OPTS="-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=8888" --name hiveserver2-standalone apache/hive:${HIVE_VERSION}
コンテナログを確認すると、Metastoreのschemaの初期化に成功し、デバッグエージェントが8888でListenし、正常にHiveServerが起動したことを確認できます。
+ : derby + SKIP_SCHEMA_INIT=false + export HIVE_CONF_DIR=/opt/hive/conf + HIVE_CONF_DIR=/opt/hive/conf + '[' -d '' ']' + export 'HADOOP_CLIENT_OPTS= -Xmx1G ' + HADOOP_CLIENT_OPTS=' -Xmx1G ' + [[ false == \f\a\l\s\e ]] + initialize_hive + /opt/hive/bin/schematool -dbType derby -initSchema SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/hive/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Listening for transport dt_socket at address: 8888 Metastore connection URL: jdbc:derby:;databaseName=metastore_db;create=true Metastore Connection Driver : org.apache.derby.jdbc.EmbeddedDriver Metastore connection User: APP Starting metastore schema initialization to 3.1.0 Initialization script hive-schema-3.1.0.derby.sql ... Initialization script completed schemaTool completed [WARN] Failed to create directory: /home/hive/.beeline No such file or directory + '[' 0 -eq 0 ']' + echo 'Initialized schema successfully..' Initialized schema successfully.. + '[' hiveserver2 == hiveserver2 ']' + export 'HADOOP_CLASSPATH=/opt/tez/*:/opt/tez/lib/*:' + HADOOP_CLASSPATH='/opt/tez/*:/opt/tez/lib/*:' + exec /opt/hive/bin/hive --skiphadoopversion --skiphbasecp --service hiveserver2 2023-05-14 06:01:05: Starting HiveServer2 Listening for transport dt_socket at address: 8888 SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/tez/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/hive/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] Hive Session ID = cbff1bee-ddb2-476b-8912-6b8c02f49266 Hive Session ID = d4327ad9-227c-4fe7-a9ec-cceb6bb26c62 OK
デバッガをアタッチするにあたり、ローカルのコードを動作中のコードと一致させる必要があるので、rel/release-3.1.3 をチェックアウトしておきます。
git fetch origin rel/release-3.1.3 git checkout rel/release-3.1.3
準備ができたので、以下のような設定でIntelliJでデバッガを起動します。

問題なくデバッガがアタッチできることを確認してください。

beelineで接続しても良いですが、IntelliJのDatabase ToolはHiveも対応しているのでIntelliJから接続します。

適当にREADME.mdのサンプルクエリを使ってテーブルを初期化し、クエリが動作することを確認します。
show tables; create table hive_example(a string, b int) partitioned by(c int); alter table hive_example add partition(c=1); insert into hive_example partition(c=1) values('a', 1), ('a', 2),('b',3); select count(distinct a) from hive_example;
あとは、実際にブレークポイントを設定し、クエリを実行してみるだけです。
試しに、org.apache.hadoop.hive.ql.Driverのcompileメソッドにブレークポイントを設定して、 select count(distinct a) from hive_example; を実行してみると、そのポイントからデバッグが可能であることがわかります。


Redis Lua script debuggerを活用する
Redisでアトミック操作を実現したい時にLua scriptを記述したい時があるが、毎回実際にRedisに投げて確認するのは非常に面倒。動作中の問題や、redis.callの返り値の確認などを行うのも非常に面倒。
公式ドキュメントにLua script debuggerが用意されているという記述を発見したので使う。 Debugging Lua scripts in Redis | Redis
今回は、ハッシュ型の値に対する簡単な比較を行うCompare and Set操作を実装する。
先に実装を出すが、あるハッシュ型のキーと、ハッシュを引数で指定し、数値の値を格納する。 数値を格納する前に、指定したキーとハッシュを用いて、既に値が存在している場合にはその値と今回指定した値を比較し、大きい場合に限り値を更新するものである。
local value = tonumber(ARGV[2]); local last_value = tonumber(redis.call('hget', KEYS[1], ARGV[1])) if last_value == nil or value > last_value then redis.call('hset', KEYS[1], ARGV[1], value) return true end return false
成功した場合にはtrueを返し、失敗した場合にはfalseを返すようにする。
先に下準備として、redis-cli経由からデータを格納しておく。
$ redis-cli 127.0.0.1:6379> hset foo bar 10000 (integer) 1 127.0.0.1:6379> hset foo baz 20000 (integer) 1 127.0.0.1:6379> hgetall foo 1) "bar" 2) "10000" 3) "baz" 4) "20000"
下準備が整ったので、デバッガを起動する。デバッガの起動には --ldb オプションを指定する。
事前にテストしたいスクリプトを用意しておき、--evalのオプションとして指定する。
ちなみに、local hoge = 0 ぐらいを記述したもので指定しても動くので最初は適当な文を一つ書いてインタラクティブに確認する、みたいな方式でもいいかもしれない。
まず、数値として10000を指定して起動する。(これは、以前と同じ大きさの値になるので更新はスキップされる)
実行のステップごとに停止し、ユーザーの入力を受け付けて次のステップに進むか、特定の変数の現在の値を確認したり、適当な文を評価したりしたりできる。
n(next)を入力すると次のステップ。p(print)を入力すると特定の変数の値を出力。e(eval)を入力すると、現在の呼び出しフレーム外でのコンテキストで文を評価。
$ redis-cli --ldb --eval test.lua foo , bar 10000 Lua debugging session started, please use: quit -- End the session. restart -- Restart the script in debug mode again. help -- Show Lua script debugging commands. * Stopped at 1, stop reason = step over -> 1 local value = tonumber(ARGV[2]); lua debugger> n * Stopped at 2, stop reason = step over -> 2 local last_value = tonumber(redis.call('hget', KEYS[1], ARGV[1])) lua debugger> print value <value> 10000 lua debugger> n * Stopped at 4, stop reason = step over -> 4 if last_value == nil or value > last_value then lua debugger> eval redis.call('hget', KEYS[1], ARGV[1]) <retval> "10000" lua debugger> eval redis.call('hget', KEYS[1], 'baz') <retval> "20000" lua debugger> n * Stopped at 9, stop reason = step over -> 9 return false lua debugger> n (nil) (Lua debugging session ended -- dataset changes rolled back) 127.0.0.1:6379>
if last_value == nil or value > last_value then の条件式にマッチせずに、return falseが実行されているのがわかります。redisからのreplyとしてはfalseに対応するnilが帰る。
次に数値として10001を指定して起動します。これは既存の10000よりも大きい値なので、更新されることを期待する。
$ redis-cli --ldb --eval test.lua foo , bar 10001
Lua debugging session started, please use:
quit -- End the session.
restart -- Restart the script in debug mode again.
help -- Show Lua script debugging commands.
* Stopped at 1, stop reason = step over
-> 1 local value = tonumber(ARGV[2]);
lua debugger> n
* Stopped at 2, stop reason = step over
-> 2 local last_value = tonumber(redis.call('hget', KEYS[1], ARGV[1]))
lua debugger> n
<redis> hget foo bar
<reply> "10000"
* Stopped at 4, stop reason = step over
-> 4 if last_value == nil or value > last_value then
lua debugger> n
* Stopped at 5, stop reason = step over
-> 5 redis.call('hset', KEYS[1], ARGV[1], value)
lua debugger> n
<redis> hset foo bar 10001
<reply> 0
* Stopped at 6, stop reason = step over
-> 6 return true
lua debugger> eval redis.call('hget', KEYS[1], ARGV[1])
<retval> "10001"
lua debugger> n
(integer) 1
(Lua debugging session ended -- dataset changes rolled back)
条件式がtrueと評価され、redis.call('hset', KEYS[1], ARGV[1], value) の実行が行われていることが分かる。
redisからのreplyとしては、trueに対応する1が返る。
デバッグが完了した時点で、実際にデバッガなしでlua scriptを実行する。
redis-cli --eval test.lua foo , bar 10000 (nil) $ redis-cli 127.0.0.1:6379> hget foo bar "10000"
$ redis-cli --eval test.lua foo , bar 10001 (integer) 1 $ redis-cli 127.0.0.1:6379> hget foo bar "10001"
$ redis-cli --eval test.lua foo , bar 9999 (integer) 1 $ redis-cli 127.0.0.1:6379> hget foo bar "10001"
問題なく動作していることが確認できる。
zkSync JavaScript SDKをrinkebyテストネットで利用する
ZK Rollupを元にしたL2プロトコルであるzkSyncについて調査し、そのJavaScript SDKの利用方法について軽く確認する。
以下のチュートリアルの内容について、実際に確認する際に必要な作業を追加で説明として加えている。
Getting started | zkSync: secure, scalable crypto payments
zkRollup
zkSyncはZK rollupに基づくL2プロトコル。
全ての資産はメインチェーンであるEthereum上で保持され、計算とストレージはオフチェーンで処理されます。 全てのトランザクションを個別に検証するのではなく、複数のトランザクションを1つのトランザクションにロールアップすることで、全ての検証と証明を同時におこおなうことができるというのがZK Rollupの考え。
- ユーザーはトランザクションに署名し、バリデータに送信する
- バリデーターは千個のトランザクションを1つのトランザクションにまとめ上げ、新しい状態のルートハッシュの暗号学的なコミットメントをメインネットのスマートコントラクトにSNARKと共に提出する。これはいくつかの正確なトランザクションを古い状態に適用した結果。
- SNARKに加え、状態の差分は安価なcalldataとしてメインチェーンネットワークに提出されます。これにより、いかなる時も誰でも状態を再構築することが可能になります。
- SNARKと状態の差分はスマートコントラクトによって検証され、全てのトランザクションの検証と妥当性はブロックの中に含まれます。
この時、各トランザクションを個別に検証するのと、オフチェーンでまとめて検証するのとでは100~200倍程度のスケーラビリティの差があり、トランザクションのコストも節約されます。
この時、ZK Rollupは以下の保証を提供します。
- バリデータが状態を破壊したり、資産を盗むことはできない。(サイドチェインとは異なり)
- バリデータが停止している状態でさえ、ユーザーは常にzkSyncスマートコントラクトから資産を取得することができます。(Plasmaとは異なり)
- ユーザーも単一の信頼できるサードパーティもZK Rollupブロックを詐欺から守るために監視を行う必要がありません。(ペイメントチャネルやOptimistic Rollupとは異なり)
環境構築
ウォレットの作成と実行環境Repl用意
npmとtruffleを先にインストールしてください。
$ truffle init $ npm install zksync $ npm install ethers
$ truffle console truffle(ganache)> const zksync = require('zksync'); undefined truffle(ganache)> zksync { Wallet: [Getter], Transaction: [Getter], ETHOperation: [Getter], submitSignedTransaction: [Getter], submitSignedTransactionsBatch: [Getter], ... } truffle(ganache)> const ethers = require('ethers'); // create provider for rinkeby test net truffle(ganache)> const syncProvider = await zksync.getDefault('rinkeby'); truffle(ganache)> const ethersProvider = ethers.getDefaultProvider('rinkeby'); // create wallet for test use truffle(ganache)> let wallet = ethers.Wallet.createRandom(); truffle(ganache)> wallet Wallet { _isSigner: true, _signingKey: [Function], address: '0x...', _mnemonic: [Function], provider: null } // attach rinkeby provider to randomly created wallet truffle(ganache)> wallet = wallet.connect(ethersProvider); Wallet { _isSigner: true, _signingKey: [Function], address: '0x...', _mnemonic: [Function], provider: FallbackProvider { _isProvider: true, _events: [], _emitted: { block: -2 }, formatter: Formatter { formats: [Object] }, anyNetwork: false, _network: { name: 'rinkeby', chainId: 4, ensAddress: '0x...', _defaultProvider: [Function] }, .. } ... } // Currenly, The balance of wallet is 0 eth. truffle(ganache)> wallet.getBalance(); BigNumber { _hex: '0x00', _isBigNumber: true }
Rinkeby Faucetでテスト用Ethの発行
EthereumテストネットワークであるRinkebyネットワークでテスト利用するためにFaucetからRinkeby用のEthereumを取得します。
(Rinkeby Authenticated Faucet)https://faucet.rinkeby.io/
「3 Ethers / 8 hours」を選択し、3 Ethersを取得します。
fundedの表示がされたタイミングで、再度 wallet.getBalance() を呼び出してみると、3 Ether近くが残高として追加されていることが確認できます。
truffle(ganache)> wallet.getBalance();
BigNumber { _hex: '0x29a2241af62c0000', _isBigNumber: true }
- (Etherscan - Rinkeby Testnet Network)https://rinkeby.etherscan.io/ Etherscanで作成したWalletのアドレスを調べてみると、fundsのトランザクションが発行されているのが確認できます。
zkSyncウォレットの作成
zkSyncウォレットで利用される秘密鍵は特別なメッセージに対してEthereumウォレットで署名した結果から暗黙的に導出される、とのことで、以下のようにしてethersのウォレットと、zkSyncのproviderを引数にzkSyncウォレットを導出します。
truffle(ganache)> const syncWallet = await zksync.Wallet.fromEthSigner(wallet, syncProvider); undefined truffle(ganache)> syncWallet Wallet { cachedAddress: '0x...', accountId: undefined, _ethSigner: Wallet { _isSigner: true, _signingKey: [Function], address: '0x...', _mnemonic: [Function], provider: FallbackProvider { _isProvider: true, _events: [], _emitted: [Object], formatter: [Formatter], anyNetwork: false, _network: [Object], _maxInternalBlockNumber: 10275589, _lastBlockNumber: -2, _pollingInterval: 4000, _fastQueryDate: 1646481989319, providerConfigs: [Array], quorum: 1, _highestBlockNumber: 10275589, _internalBlockNumber: [Promise], _fastBlockNumber: 10275589, _fastBlockNumberPromise: [Promise] } }, _ethMessageSigner: EthMessageSigner { ethSigner: Wallet { _isSigner: true, _signingKey: [Function], address: '0x...', _mnemonic: [Function], provider: [FallbackProvider] }, ethSignerType: { verificationMethod: 'ECDSA', isSignedMsgPrefixed: true } }, signer: Signer {}, ethSignerType: { verificationMethod: 'ECDSA', isSignedMsgPrefixed: true }, provider: Provider { pollIntervalMilliSecs: 1000, transport: HTTPTransport { address: 'https://rinkeby-api.zksync.io/jsrpc' }, providerType: 'RPC', contractAddress: { mainContract: '0x82F67958A5474e40E1485742d648C0b0686b6e5D', govContract: '0xC8568F373484Cd51FDc1FE3675E46D8C0dc7D246' }, tokenSet: TokenSet { tokensBySymbol: [Object] }, network: 'rinkeby' } }
zkSyncのコントラクトコードはmainContractの https://rinkeby.etherscan.io/address/0x82f67958a5474e40e1485742d648c0b0686b6e5d#code から確認することができ、このコントラクトはOpenZeppelinのUpgradableなどのコントラクトを継承しており実際には https://rinkeby.etherscan.io/address/0x59fac1d75ecf61193c7fa897035235f850076931#code へのプロキシーであることやzkSyncの実際のコントラクトコードが確認できます。
EthereumからzkSyncに資産を移動する
以下のコードでEthからzkSyncに1.0 ETHをデポジットします。この時、内部的にはRinkebyネットワークのzkSyncのコントラクトのDeposit ETHメソッドが呼び出されています。
truffle(ganache)> const deposit = await syncWallet.depositToSyncFromEthereum({ depositTo: syncWallet.address(), token: 'ETH', amount: ethers.utils.parseEther('1.0') }); undefined truffle(ganache)> deposit.awaitReceipt() { executed: true, block: { blockNumber: 108890, committed: true, verified: false } }
この場合でもetherscanでトランザクションを確認することができます。
ここで、zkSyncで資産を管理するにはzkSyncのアカウントを登録する必要があり、別の公開鍵が必要です。 zkSyncのアドレスはEthereumの資産をデポジットするか、zkSync内で資産を移動するがのどちらかにより作成されます。 しかし、作成するだけでは資産をコントロールすることができないので、zkSyncで署名を行うための署名鍵を事前に登録しておく必要があります。
// By default, the signing key isn't set. truffle(ganache)> syncWallet.isSigningKeySet() false
初期状態だと、署名鍵がセットされていない状態であり、これはアカウントが所有されていないということを示しています。別途zkSyncでのアカウント有効化手順が必要で、有効化されていない場合所有されていないアカウントとして作成されるのは、
- Ethereumでの資産の転送が正しければ、それはzkSync内でも有効だから
- 全てのアドレスが秘密鍵を持つわけではないから (コントラクトなど)
- 資産の転送は、そのアドレスの実際の所有者がzkSyncを利用し始めるまでに行われる可能性があるから
そこで、アカウントの初期化を行うために、ChangePubKeyトランザクションを介して署名鍵をセットする必要があります。
このトランザクションでは通常のEthereumトランザクションとは異なり、トランザクションデータに対するzkSync署名と、アカウントの所有権を証明するEthereum署名の2つが必要になります。
実際に署名鍵をセットするには以下の呼び出しを行い、この時かかる費用は、zkSyncノードに問い合わせが行われ可能な限り小さい費用が設定されるようになります。
truffle(ganache)> await syncWallet.setSigningKey({ feeToken: 'ETH', ethAuthType: 'ECDSA' }); Transaction { txData: { tx: { accountId: 1287821, account: '0x...', newPkHash: 'sync:...', nonce: 0, feeTokenId: 0, fee: '47200000000000', ethAuthData: [Object], ethSignature: undefined, validFrom: 0, validUntil: 4294967295, type: 'ChangePubKey', feeToken: 0, signature: [Object] } }, txHash: 'sync-tx:...', sidechainProvider: Provider { pollIntervalMilliSecs: 1000, transport: HTTPTransport { address: 'https://rinkeby-api.zksync.io/jsrpc' }, providerType: 'RPC', contractAddress: { mainContract: '0x82F67958A5474e40E1485742d648C0b0686b6e5D', govContract: '0xC8568F373484Cd51FDc1FE3675E46D8C0dc7D246' }, tokenSet: TokenSet { tokensBySymbol: [Object] }, network: 'rinkeby' }, state: 'Sent' }
このChangePubKeyトランザクションは、Rinkebyネットワークに直接送られるものではなく、zkSyncノードに送信され、後でオペレータによりまとめてRinkebyネットワークに送信されます。
そのため、zkSyncのレベルでのトランザクションはetherscanで確認するのではなくzkscanというサイトを利用します。
- (zkscan - Rinkeby)https://rinkeby.zkscan.io

ここでzkSyncウォレットで残高を確認すると、転送したEthが反映されているのを確認することができます。
truffle(ganache)> syncWallet.getBalance('ETH'); BigNumber { _hex: '0x0de08bc60c284000', _isBigNumber: true } truffle(ganache)> let zkSyncBalance = await syncWallet.getBalance('ETH') undefined truffle(ganache)> ethers.utils.formatEther(zkSyncBalance); '0.9999528'
getAccountState を呼び出すことで、アカウントが所有する全てのトークンを確認することができます。
truffle(ganache)> await syncWallet.getAccountState() { address: '0x...', id: 1287821, depositing: { balances: {} }, committed: { balances: { ETH: '999952800000000000' }, nfts: {}, mintedNfts: {}, nonce: 1, pubKeyHash: 'sync:...' }, verified: { balances: { ETH: '1000000000000000000' }, nfts: {}, mintedNfts: {}, nonce: 0, pubKeyHash: 'sync:...' }, accountType: 'Owned' }
zkSyncからEthereumに資産を移動する
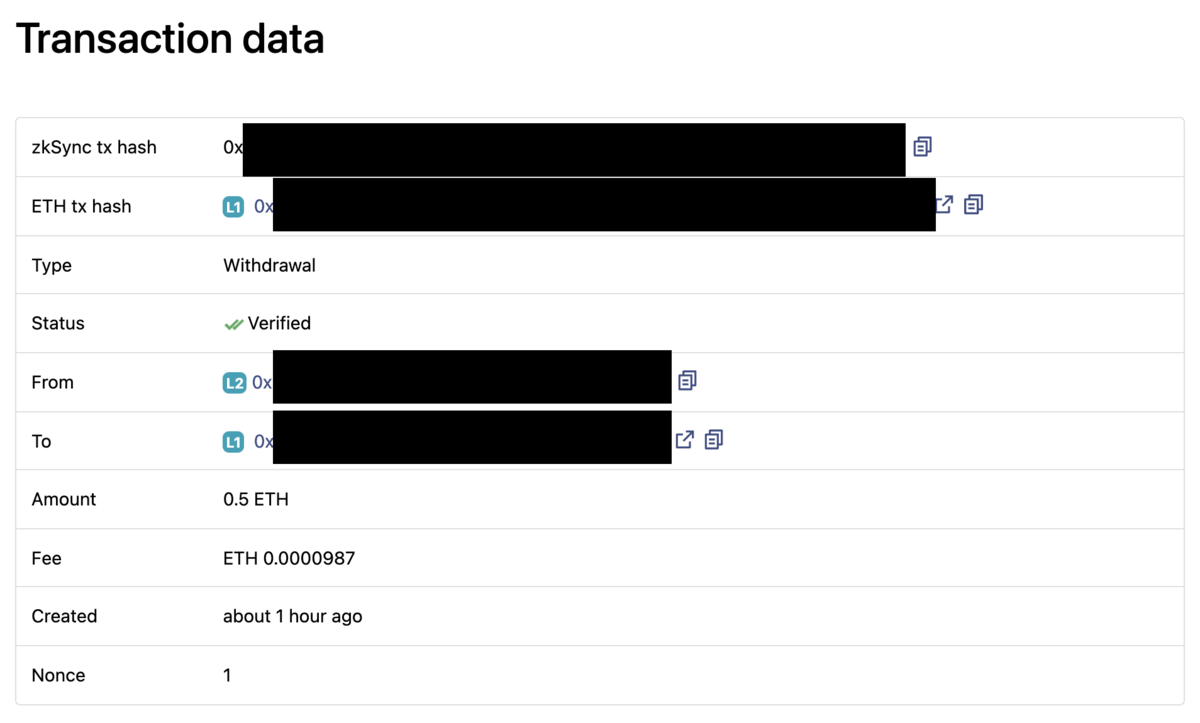
withdrawFromSyncToEthereum によって、zkSyncからEthereumに引き出しを行うことができます。
truffle(ganache)> let withdraw = await syncWallet.withdrawFromSyncToEthereum({ ethAddress: wallet.address, token: 'ETH', amount: ethers.utils.parseEther('0.5') }); truffle(ganache)> zkSyncBalance = await syncWallet.getBalance('ETH') undefined truffle(ganache)> ethers.utils.formatEther(zkSyncBalance); '0.4998541' // This is not immediately reflected as the withdrawal from L2 to L1 needs to get finality at L1. truffle(ganache)> ethers.utils.formatEther(ethBalance); '1.999937400998935817' // After a while, ETH tx will be submitted and confirmed. After that, eth balance is reflected. truffle(ganache)> ethBalance = await wallet.getBalance() undefined truffle(ganache)> ethers.utils.formatEther(ethBalance); '2.499937400998935817'
このとき、zkSyncのバリデータによってrollupされたトランザクションでまとめて引き出しが実行されます。
zkscanからETH tx hashを確認することで、EthereumのどのトランザクションによってzkSyncコントラクトから自分のアドレスに資産が転送されたかを確認することができます。
JavaサーバーサイドエンジニアのEthereum開発入門
Ethereumのスマートコントラクトを活用したアプリケーション開発についていろいろやった内容をまとめる
Ethereumおさらい
コンピュータサイエンスの観点から見たイーサリアムは、決定論的であるものの実質的に制約のない状態マシンであり、グローバルにアクセス可能なシングルトン状態(単一の状態)と、その状態に変更を加える仮想マシンで構成されています。
実用的な観点から言うと、イーサリアムは、スマートコントラクト(smart contract)と呼ばれるプログラムを実行する、グローバルに非中央集権化された、オープンソースの演算の基盤です。
Andreas M. Antonopoulos; Gavin Wood. マスタリング・イーサリアム ──スマートコントラクトとDAppの構築 (Kindle の位置No.565-569).
サーバーサイドエンジニアから見たEthereum
厳密さを完全に抜くと、
- パブリックに公開された
- 誰でも操作可能で
- 改竄不可能で
- トリガーやイベント通知システムを持ち
- 結果整合性を持つ
分散データベース みたいなもんとして考えられます。
Ethereumブロックチェーンは、Yellow Paperの仕様を実装した共通のプロトコルで通信するEthereumクライアントプログラムが相互に接続して形作られるネットワークです。
- このクライアントプログラムによって、ブロック検証やデータの保持、状態の導出、クライアントAPI、プログラム実行環境が提供されます。
クライアントはさまざまな言語で実装され、サポートする機能によってクライアントの種類が変わります
Ethereum Yellow Paper: https://ethereum.github.io/yellowpaper/paper.pdf
Ethereum Virtual Machine [EVM]
イーサリアムはチューリング完全であり、EVM(イーサリアム仮想マシン)上でプログラム(スマートコントラクト)を実行可能です。 つまり、任意の操作を行うスマートコントラクトを実行可能ですが、以下の制約があります。
- EVM上で利用可能なコンポーネントへのアクセスのみ許可されます
つまりEVM上で実行されるプログラムではネットワークアクセスやEVM外のストレージアクセスは許可されません
JVMなどとは異なり、実行順序の決定がEVM外部で決定されるのでスケジューリング機能がありません
- スマートコントラクトは、各イーサリアムクライアントのEVM上で実行されるので、決定的である必要があります
- つまり非決定的である乱数などの値を利用することができません
- 一方、「ガス」というEVMバイトコード毎に割り当てられている実行コストによって実行上限が決定される。このガスの上限に到達した時点でコードの実行がrevertされることになる => 停止性問題への対応
EVM上で動かすことができるのは、EVM独自のバイトコードで記述された命令セットです。 実際にはEVMバイトコードにコンパイル可能な、Solidityなどのスマートコントラクト用のプログラミング言語でコードを記述して、コンパイルすることでEVMバイトコードを生成可能です。
- 算術演算とビット単位の論理演算
- 実行コンテクストに関する問い合わせ
- スタック、メモリ、ストレージへのアクセス
- 制御フローに関する操作
- ロギング、関数コール、その他の演算子
Andreas M. Antonopoulos; Gavin Wood. マスタリング・イーサリアム ──スマートコントラクトとDAppの構築 (Kindle の位置No.10163-10164).
Ethereumの状態更新
- スマートコントラクトを宛先にして以下のパラメータなどを指定したトランザクションを発行することにより、スマートコントラクトを実行します。
- 引数
- 実行する関数を示すセレクタ
- 実行のために設定するガス
- スマートコントラクトの実行結果は決定的であり、全てのクライアントで実行される結果は同じになります。正しくスマートコントラクトが実行されると、イーサリアムの状態であるストレージが更新され、やがて全てのクライアントが同一の状態について合意することになります。
実際のアプリケーションアーキテクチャの例
よくEthereum上で動作するアプリケーションとしてDAppsが有名ですが、これはバックエンドをEthereumとし、特定の中央集権のインフラストラクチャによらずアプリケーションを提供するものです。 ブロックチェーン上のアドレスの所有権というのは秘密鍵と署名によって担保されているので、プライベートネットワーク内のServer Side Applicationからでもトランザクションを送信したり現在のチェーンの状態を取得することは可能です。

分権型 予約型純広告アドネットワークを作る
では実際に以下の構成で分権型の純広告アドネットワークを作っていきましょう。
- Ethereum上の広告ネットワークコントラクト
- 広告枠と広告を管理可能なDApps
- 広告枠に対して実際に広告を配信するサーバアプリケーション
- 承認と配信のための実際の広告情報をホストする管理サーバアプリケーション
アドネットワークの全体像
では開発するアドネットワークの全体像は以下のようになります。

(DAppsと言っているが、ちょっと時間の都合上ローカルサーバで動かすためにホスティングがDecentralizedではないのは :sorry: )
分権型 予約型純広告アドネットワークで広告を配信するまでの流れ
実際に開発の説明に入る前に、どのような流れで広告配信が行われるかを確認します。
- アドネットワークコントラクトがEthreumネットワーク上にデプロイされる
- 広告枠主はDAppsにアクセスし、自身の所有する広告枠を作成するトランザクションを発行します。広告枠に関する情報はコントラクトの状態として記録されます。
- 広告主はDAppsにアクセスし、広告管理バックエンドを利用するためにEthereumアカウントによる署名を用いてログインを行います。
- DApps上で、広告を配信したい広告枠を探し、その広告枠に掲載するための広告情報を事前に作成します。これはAdFormatV1というフォーマットを定義します。AdFormatV1に沿ったデータは、広告承認フローと広告配信フローで利用されます。
interface AdFormatV1 { inventoryId: number; ownerAddress: string; startTime: number; endTime: number; adPrice: number; adTitle: string; adDescription: string; landingPageUrl: string; displayImageUrl: string; nonce: string; }
- Ethereumアカウントでログインしている場合、広告管理バックエンドで広告ストレージと配信管理が利用可能です。まず、広告情報を、広告承認/配信で利用できるように広告管理バックエンド経由でストレージにアップロードします。
- AES-GCM方式の128bit長の共通鍵を生成しておきます
- AdFormatV1をJSONにエンコードします
- 共通鍵を用いてエンコードされたデータを暗号化します
- 広告枠のRSA Public Keyを用いて共通鍵を暗号化します
${version}:${encryptedEncryptionKey}:${ciphertext}の形式で、広告管理バックエンドにアップロードします。- 広告管理バックエンドでは、ログインしていることを確認し、アップロードされたデータの SHA-3(Keccak)を計算し、このハッシュでアクセスできるように静的ホストします。
- レスポンスとして、SHA-3ハッシュの値を返却します
これを、広告枠主のPublic Keyと、事前に入手しておいた配信サーバ用のPublic Keyの両方で処理しておきます。
- 広告枠主が自分の所有する広告枠の承認待ちの広告をチェックします
- 広告枠主は、承認待ちの広告のSHA-3ハッシュを用いて、広告管理バックエンドから暗号化されたAdFormatV1データをダウンロードします。自身の秘密鍵を用いて、共通鍵を複合化します。そして共通鍵によってAdFormatV1データを複合します。この結果を閲覧し、審査作業を行います。
広告枠主が広告の掲載が問題ないと判断すれば承認のためのトランザクションを実行し、コントラクト上で配信可能なステータスに遷移します。
広告主は広告管理バックエンドを介して、広告配信サーバに対し、配信前に事前に配信有効化を行います
- 広告配信サーバは、定期的にコントラクトの状態をチェックし、配信設定が有効化されているものについて、ロードを行います。ロードの際に、公開鍵を用いてAdFormatV1を複合しlandingPageやdisplayImageなどの情報をキャッシュしておきます。
- 広告枠主が事前にJS SDKにinventoryIdを設定し、広告枠のメディアページに設置しておきます。
- エンドユーザーがアクセスしたときに、inventoryIdを含めてリクエストし、配信サーバでキャッシュされている広告のうちランダムなものを返します
- JS SDKで表示します
では実際にコントラクトの開発から見ていきます。
アドネットワークコントラクトの開発
- Solidityによってスマートコントラクトを開発します
SolidityはC++, Python, JavaScriptを参考に作られたスマートコントラクト向けの静的言語です
- int8,32,256, uint8,32,256, 配列, mappingなど基本的なデータ型
- if, forなど基本的な制御構文
- address,payable address型, memory/storage修飾子, イベントなどのSolidity特有の型
- Structs 構造体
https://solidity-jp.readthedocs.io/latest/ 詳細はドキュメントで
Ethereum 開発エコシステム
- IntelliJ: 開発環境, Solidityプラグインがあり開発可能. サジェスト弱め.
- solc: Solidityのコンパイラ
- Truffle: コンパイル,テスト,パッケージ化のためのツール
- Ganache: GUIで操作可能なローカルEthereum環境
最近はHardhatというツールがTruffleよりも流行りらしい。
アドネットワークコントラクトの状態
状態として以下を保持します
- カウンタ
- 広告枠ID採番のためのカウンタ
- 広告ID採番のためのカウンタ
- データ
- 広告枠Set
- 広告Set
- マッピング型
- 承認待ちの広告のためのadId => inventoryId mapping
- 承認済みの広告のためのadId => inventoryId mapping
- 広告主の現在の広告数のためのaddress => adCount mapping
- 広告枠主の現在の広告枠数のためのaddress => inventoryCount mapping
- 広告枠に登録されている現在の広告数のためのinventoryId => adCount mapping
- 広告枠に登録されている現在の承認待ちの広告数のためのinventoryId => adCount mapping
アドネットワークコントラクトで提供する関数
- 広告枠の作成
function createAdInventory(string memory name, string memory uri, string memory publicKey, uint256 floorPrice) external)
- 広告枠の削除 - 広告が1件も登録されてなければ広告枠を削除します
function removeAdInventory(uint256 _inventoryId) external
- 広告の作成 - 広告を作成する際に広告枠のフロアプライスを超えるデポジットが必要です
function createAd(uint256 _inventoryId, bytes32 _hash, bytes32 _hashForDelivery, uint32 _start, uint32 _end) external payable
- 広告の承認 - 広告を承認すると配信対象になり配信期間の間だけ配信されます
function approveAd(uint256 _inventoryId, uint256 _adId) external
広告の却下 - 広告を却下すると広告は削除されデポジットは返却されます
function rejectAd(uint256 _inventoryId, uint256 _adId) external
広告枠から広告の回収 - 広告配信が完了した後、広告枠を占有されるのを防ぐため回収して削除する必要がありますが、広告主と広告枠主の両方がこの操作が可能です。広告主が行う場合、インセンティブとしてデポジットされている価格のうち一部が返却され、回収された時点で広告枠主のアドレスに料金が支払われます。
function collectAd(uint256 _inventoryId, uint _adId) external
- 広告枠の広告の取得
function getAdsOf(uint256 _inventoryId) external view
- 広告主アドレスから広告の取得
function getAdsByOwnerAddress(address _ownerAddress) external view
- 広告枠主アドレスから広告枠の取得
function getInventoriesByOwnerAddress(address _ownerAddress) external view
- 広告枠の取得
function getInventory(uint256 _inventoryId) external view
- 広告枠の取得 by (offset, limit)
function getInventories(uint offset, uint limit) external view
スマートコントラクトでデータの削除を考える
ブロックチェーンで改竄やデータの削除ができない、というのは履歴データとして残るのでデータが削除できない、という話です。スマートコントラクトの状態データとして、追加のみをサポートしてしまうとストレージの中にゴミデータが大量に残ってしまいます。 ゴミデータが増えれば、EVM上で処理をする際に追加のコストを払う必要が出てきますし、最悪ガス代がブロックガス上限を超えることでコントラクトが全く動作しないものになってしまう恐れもあります。
そのため、コントラクトの状態データは不要になった時点で削除することも考えなければなりません。
しかし、Solidityで基本的に提供されているコレクションのデータ構造は固定長/可変長配列とマッピングに限られます。
可変長配列を使うケース
では単なる可変長配列をマスターデータを管理するためのデータ型とします。
可変長配列でサポートされている操作は、array[x] のような添字アクセスとdelete array[x]のような特定の要素の削除に加え以下のメソッドがサポートされています。
length: 配列の長さを返しますpush: 配列の最後に要素を追加しますpop: 配列の最後から要素を削除します
広告構造体を格納するAd[] storage adsフィールドに新しい広告を追加する時はpushを呼び出せば十分です。
しかし、ある広告IDをもつ広告を削除したい時にどうすれば良いでしょう?
普通に削除すると、popだと最後の要素しか削除できないですし、deleteを使うと削除した要素が歯抜けになります。配列を毎回作り直すと、これはコントラクトの状態を大きく変化させるガスコストが非常に高い操作であるので避けなければなりません。
Array Members - Solidity https://solidity-jp.readthedocs.io/ja/latest/types.html?highlight=array#array-members
EnumerableSet
解決策として、SolidityでHashSet相当を実装します。
ここで OpenZeppelin というSolidityのライブラリでは、EnumerableSetという32bytes値をkey、32bytes値をvalueとするHashSetが定義されています。
これはそのままだと目的の利用ができないので、参考にしつつInventorySet, AdSetというデータ型を新しく作成します。
struct InventorySet {
Inventory[] _values;
mapping(uint256 => uint256) _idxMapping;
}
struct AdSet {
Ad[] _values;
mapping(uint256 => uint256) _idxMapping;
}
内部で、「Key => 配列のIndexのmapping」と、「データを保持する配列」の二つを保持します
- OpenZeppelin EnumerableSet.sol https://github.com/OpenZeppelin/openzeppelin-contracts/blob/master/contracts/utils/structs/EnumerableSet.sol
EnumerableSetの実装を確認してみます。これは以下の操作を行えます。
add: 要素の追加をO(1)で行います. 単に配列の最後にpushし、KeyのIndexにlengthの値をセットします。remove: 要素の削除をO(1)で行います. keyが存在する場合、まずkeyが示すindexの要素と最後の要素をスワップします。スワップした後、popによって最後の要素を削除することで配列のフラグメンテーションが発生せずに削除可能ですcontains: 要素の存在判定をO(1)で行います.- 内部の配列に直接アクセスして要素を列挙したりすることも可能です
この実装により、要素の削除がO(1)で行えるようになるのでガスコストを節約しつつストレージの整理を行うことができます。
スマートコントラクトのテスト
Truffleではスマートコントラクトの以下のテストをサポートしている
- JavaScriptでのクライアントサイドテスト
- Solidityでコントラクトを直接呼び出すテスト
Solidityでのテストは以下のように記述できる
contract AdNetworkTest {
address deployedAddress = DeployedAddresses.AdNetwork();
AdNetwork adNetwork = AdNetwork(deployedAddress);
InventoryOwner inventoryOwner = new InventoryOwner(adNetwork);
function testCreateAdInventory() public {
string memory name = "sample_inventory";
string memory uri = "https://example.com/";
string memory publicKey = "dummy_public_key";
uint256 floorPrice = 0.01 ether;
uint256 inventoryId = inventoryOwner.createAdInventory(name, uri, publicKey, floorPrice);
Assert.equal(inventoryId, 1, "Ad Inventory can be created");
(uint256[] memory inventoryIds,,,,,) = adNetwork.getInventoriesByOwnerAddress(address(this));
Assert.equal(inventoryIds.length, 0, "Inventory can't be retrieve by not owner address");
(inventoryIds,,,,,) = inventoryOwner.getInventoriesByOwnerAddress();
Assert.equal(inventoryIds.length, 1, "Inventory can be retrieve by owner address");
}
}
管理用のDAppsを開発する
次に、広告主と広告枠主が実際に広告枠や広告を管理するためのフロントエンドアプリケーションであるDAppsを開発していきます。
主に以下の項目がサポートされます。
管理用のDAppsを開発する - フロントエンドからイーサリアムを操作する
フロントエンドからMetamaskなどのEthereum Providerを通してEthereumネットワークに接続するためのライブラリとして、web3.jsというJavaScriptのライブラリが利用できる。
// Modern dapp browsers... if (window.ethereum) { const web3 = new Web3(window.ethereum as any); // Request account access if needed await (window.ethereum as any).enable(); // Acccounts now exposed web3.xxx();
ChromeにMetamaskなどのProvider Extentionがインストールされていれば、Providerを検出してそれをもとにWeb3オブジェクトを生成し、このオブジェクトを介してフロントエンドでEthereumとやりとりをすることができる。
管理用のDAppsを開発する - コントラクトを操作する
- スマートコントラクトをビルドすると、ABI(Application Binary Interface)というスマートコントラクトとやりとりを行うためのインタフェース定義も出力される。 https://raw.githubusercontent.com/deftfitf/blockchain-adnetwork/master/adnetwork-contracts/client/src/contracts/AdNetwork.json
- このjsonを、先ほどのweb3.jsで提供されるコントラクトクラスをインスタンス化する際の引数に渡すことで、コントラクトを操作するためのオブジェクトが生成できる。
const contract = new web3.eth.Contract( abi as any, deployedNetwork && deployedNetwork.address, )
管理用のDAppsを開発する - コントラクトの操作を型安全にする
web3.jsでコントラクトを操作する際、型がないので何を書いているのか分からなくなる。 TypeChainというnpmでインストール可能な、ABIからTypeScriptの型定義を出力してくれるツールがある。 * TypeChain https://github.com/dethcrypto/TypeChain
以下のようなコマンドで型定義を生成し、
npx typechain --target=web3-v1 --out-dir=src/types/web3-v1-contracts src/contracts/**
const contract = (new web3.eth.Contract( abi as any, deployedNetwork && deployedNetwork.address, ) as any) as AdNetwork;
このようにキャストすることでコントラクトから呼び出し可能な関数を補完することができて快適になる。
それ以外は特に普通にフロントエンドアプリ書く時と特に変わりないはず。
管理用Server Side Applicationを開発する - 実装する機能
管理用アプリケーションを開発する - Ethereumアカウントでのログイン実装
- 誰でも任意の広告枠の広告配信を有効化したりできてしまうと問題です。広告枠の配信有効化や、配信に利用する画像アップロード機能などは、特定のアドレスのEthereumアカウントの所有者にのみ限定したりする必要があります。
- 通常のEthereumのトランザクションは、そのアカウントの秘密鍵による署名によって所有を証明します。Ethereumアカウントでのログインも、同様の仕組みで実装します。
以下の手順でログイン処理を行います。
- ログインしたいEthereumアカウントに対して一度だけ有効なランダムなチャレンジ文字列を生成するようにバックエンドにリクエストする[UUID]
- DApps上でチャレンジ文字列に対してMetamaskを介してログインしたいEthereumアカウントで署名を行う
- 署名後の文字列と、所有を証明したいEthereumアカウントをログインエンドポイントに投げる
- 対象のアカウントのチャレンジ文字列と送信された署名を用いてアドレスを複合する. (EthereumアドレスはECDSA公開鍵の後ろ20bytesなので、ECDSAの署名検証の処理によりアドレスが復元可能)
- 復元されたアドレスとログインリクエストしたアドレスが同一であればログイン許可し、セッションを発効。以後Spring Sessionでウンタラカンタラ。
配信用アプリケーションを開発する - JavaからEthereumを操作するには
- Java 開発者のためのイーサリアム(https://ethereum.org/ja/java/) というまさにうってつけの公式ページがある。
JavaからEthereumを操作するにはWeb3Jというライブラリを利用する。
EthereumクライアントはJSON-RPCを提供しているため、JSON-RPCを介してEthereumを操作することができる。
なので、基本的に定期的に実行するローディング処理によって対象のコントラクトからデータをロードするだけで普通にDBからデータをロードするようなものと変わりません。